Une IA qui apprend de millions de patients sans jamais voir un seul dossier. Ce n’est pas une promesse marketing. C’est ce que le Swarm Learning commence à démontrer — et pourquoi ça change quelque chose de concret pour la médecine de demain.
En 2025, une équipe européenne tente d’entraîner une IA capable de détecter précocement un cancer du poumon à partir de scanners thoraciques. Le projet est sérieux, le financement solide, l’équipe compétente.
Le modèle fonctionne. Dans un hôpital.
Dès qu’il est testé dans un second établissement — même pays, même pathologie, même type de scanner — ses performances chutent de manière significative. Pas un effondrement brutal, mais suffisamment pour le rendre cliniquement inutilisable hors de son contexte d’origine.
Ce n’est pas un bug. L’algorithme n’a pas de défaut. Le problème est ailleurs : le modèle a appris sur les données d’un seul hôpital, avec ses machines, ses protocoles, sa démographie. Il n’a jamais été exposé à la diversité du réel. Et cette diversité, précisément, est ce qui lui permettrait de fonctionner partout.
C’est le paradoxe central de l’IA médicale aujourd’hui : les données qui permettraient de construire des modèles robustes existent. Elles sont réparties dans des milliers d’établissements à travers le monde. Mais elles ne peuvent pas circuler — pour des raisons réglementaires, éthiques, et pratiques parfaitement légitimes.
Le Swarm Learning est l’une des réponses les plus sérieuses à ce problème. Pas la plus médiatisée. Peut-être la plus solide.
1 — Le mur invisible de la donnée médicale
Pour comprendre pourquoi le Swarm Learning est apparu, il faut d’abord mesurer l’ampleur du problème qu’il tente de résoudre.
Selon l’OCDE (2024), près de 90 % des données médicales mondiales ne quittent jamais les hôpitaux qui les ont produites — non par mauvaise volonté, mais par contrainte réglementaire, éthique et opérationnelle. Dans le même temps, Nature Digital Medicine montre que trois modèles médicaux sur quatre perdent l’essentiel de leur performance lorsqu’ils sont testés dans un établissement différent de celui où ils ont été entraînés.
Le problème n’est donc pas la quantité de données disponibles dans le monde. C’est leur diversité — inaccessible par construction.
Ce phénomène a un nom technique : le dataset shift. Ses conséquences sont très concrètes. Un modèle entraîné sur des populations caucasiennes détecte moins bien certaines pathologies dermatologiques sur peaux foncées. Un modèle calibré sur les scanners d’un constructeur donne des résultats dégradés sur les machines d’un autre. Un modèle développé dans un grand CHU universitaire ne se comporte pas de la même façon dans un hôpital rural. Ces biais ne sont pas anecdotiques — ils sont structurels. Et tant que les données restent en silo, ils sont difficiles à corriger. (Ce blocage est analysé en détail dans un prochain article sur les coûts réels de l’entraînement d’une IA médicale. À paraître.)
2 — Pourquoi la centralisation a échoué
La réponse évidente à ce problème — celle qui a dominé pendant plus d’une décennie — était de centraliser. Construire de grands entrepôts de données, agréger les dossiers de millions de patients, créer des bases communes sur lesquelles entraîner des modèles puissants.
Cette stratégie a produit des résultats réels dans certains contextes. Mais elle s’est heurtée à des obstacles structurellement difficiles à surmonter.
Le premier est réglementaire. Le RGPD en Europe, le HIPAA aux États-Unis, et les législations nationales encadrent strictement le transfert et l’agrégation de données de santé. Le futur Espace Européen des Données de Santé (EHDS), dont la mise en œuvre progressive est attendue à partir de 2025-2026, va dans le sens d’une meilleure interopérabilité — mais avec des garde-fous renforcés, pas une libéralisation.
Le second est la confiance des patients. Les grandes fuites de données des dernières années ont durablement affecté leur disposition à voir leurs données circuler. La fuite Viamedis/Almerys en France en 2024 a concerné 33 millions d’assurés. Ce n’est pas sans conséquence sur la façon dont les patients partagent — ou retiennent — leurs informations médicales. [Pourquoi vos données de santé valent de l’or] revient en détail sur cette économie de la méfiance et ses effets concrets sur la qualité du soin.
Le troisième est opérationnel. Centraliser des données médicales à grande échelle coûte cher — en infrastructure, en sécurité, en gouvernance. Plusieurs projets ambitieux ont été abandonnés ou réduits faute de modèle économique viable. À cela s’ajoute un problème souvent sous-estimé : les hôpitaux n’arrivent pas à partager leurs données même entre eux, faute de systèmes d’information compatibles et de standards communs.
La conclusion qui s’impose progressivement : on ne peut plus déplacer la donnée médicale. La seule chose qui peut encore circuler, c’est l’intelligence.
3 — Le Federated Learning : une avancée réelle, des limites persistantes
C’est dans ce contexte qu’est apparu le Federated Learning — l’apprentissage fédéré — au milieu des années 2010, popularisé notamment par Google pour des applications grand public avant d’être adapté au domaine médical.
Le principe représente une avancée conceptuelle importante : plutôt que de déplacer les données vers un modèle central, on déplace le modèle vers les données. Chaque hôpital entraîne localement une version du modèle sur ses propres données, puis envoie uniquement les mises à jour mathématiques — les gradients — à un serveur central qui les agrège pour améliorer le modèle global. Les données brutes ne bougent jamais.
En pratique, le Federated Learning a permis des collaborations qui n’auraient pas été possibles autrement. Des consortiums hospitaliers ont pu entraîner des modèles de détection de pathologies sur des données réparties dans plusieurs pays sans jamais les centraliser.
Mais ses limites sont aujourd’hui bien documentées.
La première est architecturale : le serveur central reste un point de vulnérabilité et de pouvoir. Qui le contrôle ? Avec quelles garanties pour les hôpitaux participants ? Dans la pratique, les établissements qui rejoignent un projet fédéré délèguent une partie du contrôle à l’opérateur du serveur central — souvent une entreprise privée ou une institution académique avec ses propres intérêts.
La seconde est sécuritaire. Des chercheurs — notamment Zhu et al. dans leurs travaux sur le Deep Leakage from Gradients (2022) — ont démontré qu’il est possible, dans certaines conditions, de reconstruire des données patients à partir des seuls gradients échangés. Les ajustements mathématiques que le modèle envoie au serveur central peuvent, s’ils ne sont pas correctement protégés, révéler des informations sur les données qui les ont produits. C’est un problème non trivial, et les solutions de protection existantes ont un coût en performance.
La troisième est politique : les hôpitaux participants restent dans une position de fournisseurs, pas de décideurs. Ils contribuent au modèle commun sans avoir de réel pouvoir sur son utilisation, sa commercialisation éventuelle, ou les conditions dans lesquelles il sera déployé.
Le Federated Learning a résolu le problème du déplacement des données. Il n’a pas résolu la question de la souveraineté.
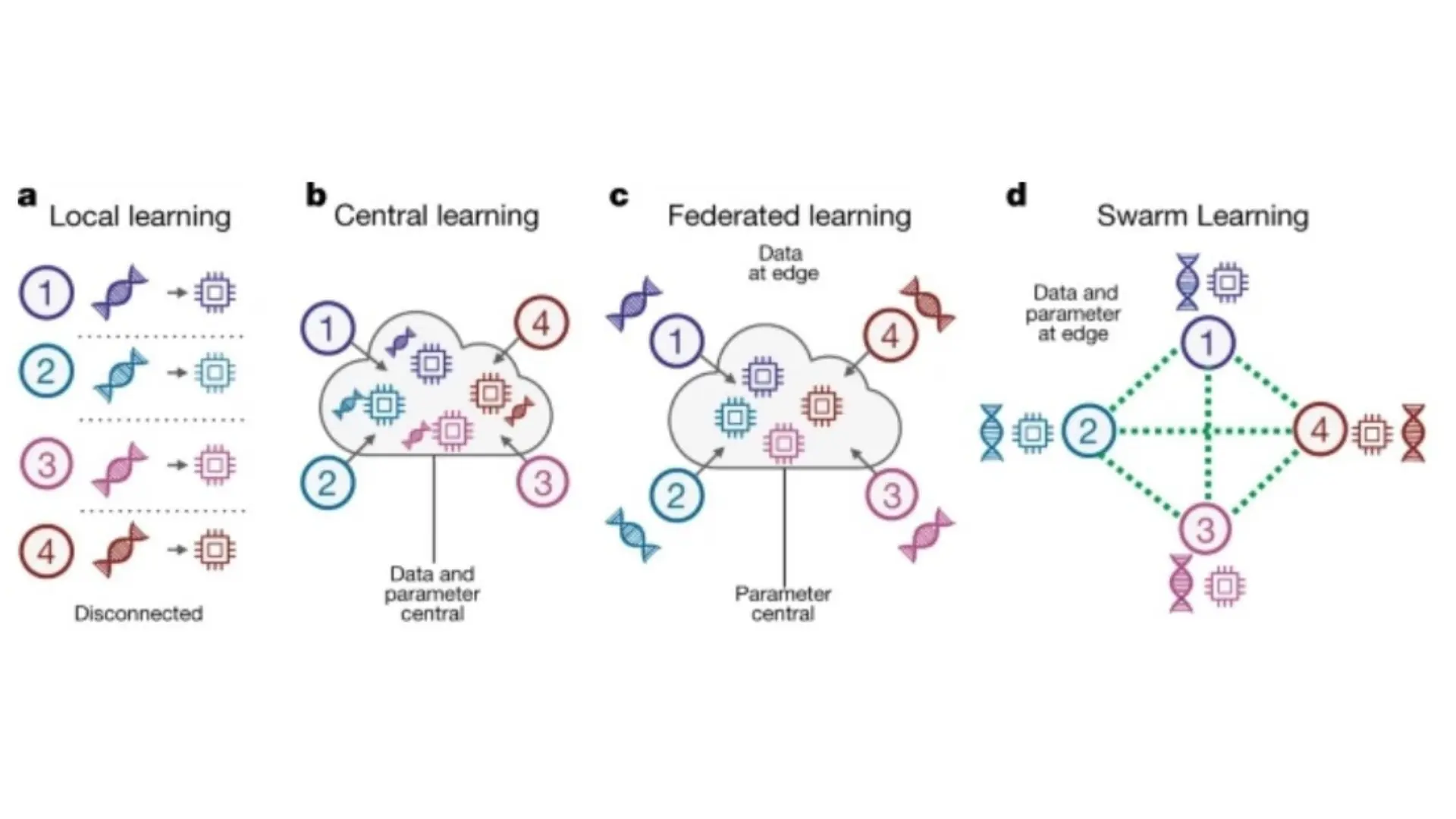
4 — Le Swarm Learning : l’architecture sans centre
Le Swarm Learning émerge en 2020 d’une publication dans Nature, issue d’une collaboration entre le German Cancer Research Center (DKFZ) et HPE. L’idée de départ est radicale dans sa logique : si le serveur central est le problème, supprimons-le.
Dans une architecture Swarm, il n’existe aucun serveur central, aucune autorité unique, aucun point de contrôle. Le réseau est entièrement pair-à-pair.
Concrètement, voici ce qui se passe : chaque hôpital participant conserve intégralement ses données. Localement, il entraîne le modèle sur ses propres données et produit des paramètres — les ajustements appris. Ces paramètres sont partagés avec les autres nœuds du réseau, mais jamais les données brutes. Un mécanisme de consensus distribué — s’appuyant sur une blockchain utilisée comme journal d’audit, pas comme base de données — valide collectivement les mises à jour avant de les intégrer au modèle global. Aucun participant ne peut imposer ses paramètres seul. Le modèle final est le produit d’un consensus entre pairs.
La différence avec le Federated Learning n’est pas seulement technique. Elle est politique. Dans un Swarm, chaque hôpital est un pair, pas un contributeur. Il a le même poids, le même accès, le même pouvoir de validation que les autres. Il n’y a pas de propriétaire du modèle — ou plutôt, tous les participants en sont copropriétaires.
C’est précisément ce changement d’architecture que certains acteurs tentent aujourd’hui de déployer concrètement dans des environnements hospitaliers réels.
5 — Ce que les chiffres disent
Les résultats publiés par le DKFZ et ses partenaires sont significatifs, même s’il faut les lire avec la prudence habituelle due aux premières publications dans un domaine émergent.
Sur la détection de la leucémie, le modèle Swarm entraîné sur des données réparties dans plusieurs hôpitaux européens a atteint des performances comparables à un modèle centralisé — avec des données que la centralisation n’aurait pas permis de rassembler légalement.
Sur les maladies rares, les gains sont encore plus nets. Un modèle entraîné en silo sur les données d’un seul hôpital manque structurellement de cas pour apprendre correctement. Le Swarm permet d’agréger des signaux faibles répartis dans de nombreux établissements : les études disponibles montrent des gains de performance supérieurs à 25 % par rapport aux modèles mono-établissement sur ces pathologies.
Sur la robustesse aux attaques, les expérimentations du DKFZ ont soumis l’architecture à des attaques adversariales simulées — des tentatives de manipulation du modèle par injection de données corrompues. Plus de 85 % de ces attaques ont été absorbées sans dégradation significative, là où les architectures fédérées classiques montraient des fragilités importantes.
La raison est structurelle : pour compromettre un modèle Swarm, il faudrait corrompre simultanément un nombre suffisant de nœuds indépendants pour atteindre le consensus. C’est une attaque d’une complexité sans commune mesure avec le compromis d’un serveur central unique.
Ces chiffres sont prometteurs. Ils restent à confirmer à plus grande échelle et sur des cas d’usage plus variés — c’est la limite honnête de tout travail de recherche à ce stade de maturité.
6 — L’enjeu européen
Le Swarm Learning arrive à un moment particulier pour l’Europe.
Le continent dispose de systèmes de santé publics qui ont produit des décennies de données cliniques de haute qualité. Il a une tradition forte de protection des données personnelles. Et il a une ambition affichée — notamment à travers l’EHDS — de ne pas laisser l’IA médicale se développer exclusivement sous contrôle américain ou chinois.
Mais il a jusqu’ici échoué à traduire ces atouts en modèles d’IA médicale compétitifs. La raison principale : l’impossibilité légale et politique de centraliser les données à l’échelle nécessaire. [La souveraineté numérique en santé : le combat invisible de l’Europe pour ses données] revient en détail sur ce que l’Europe tente de construire — et les obstacles qui freinent encore cette ambition.
Le Swarm Learning change cette équation. Il offre la possibilité d’entraîner des modèles sur des populations européennes larges et diversifiées — françaises, allemandes, scandinaves, méditerranéennes — sans jamais extraire une donnée de son pays d’origine. Chaque établissement reste souverain. Chaque pays reste conforme à sa législation. Et le modèle résultant est meilleur que tout ce qu’un seul pays pourrait produire seul.
La question politique sous-jacente est simple : qui va entraîner les IA médicales qui soigneront les Européens ? Si l’Europe ne développe pas ses propres modèles, elle utilisera ceux entraînés sur des populations américaines ou chinoises — avec tous les biais que cela implique pour ses patients.
7 — Ce que le Swarm ne résout pas
Un article honnête sur le Swarm Learning doit aussi nommer ses limites.
La première est la complexité opérationnelle. Coordonner un réseau de pairs sans serveur central est plus difficile à mettre en œuvre qu’une architecture centralisée. Les mécanismes de consensus prennent du temps. À grande échelle, avec des centaines d’établissements, les questions d’ingénierie restent ouvertes.
La seconde est la standardisation des données. Pour que des hôpitaux de différents pays puissent contribuer au même modèle, leurs données doivent être dans des formats comparables. C’est loin d’être le cas aujourd’hui — l’interopérabilité des systèmes d’information hospitaliers reste un chantier non résolu dans la plupart des pays européens. (Un article à paraître reviendra sur comment les hôpitaux ont perdu le contrôle de leur propre architecture informatique.)
La troisième est la gouvernance. Qui décide des cas d’usage autorisés ? Qui peut rejoindre le réseau ? Comment exclure un participant malveillant ? Ces questions ont des réponses techniques partielles — le mécanisme de consensus — mais elles ont surtout besoin de réponses juridiques et institutionnelles qui n’existent pas encore clairement.
Le Swarm Learning est une avancée réelle. Ce n’est pas une solution clé en main.
Conclusion
L’IA médicale n’a jamais été bloquée par ses algorithmes. Elle a été bloquée par un modèle hérité : centraliser, copier, posséder.
Le Swarm Learning propose une logique différente — collaborer sans céder, apprendre sans extraire. Les résultats disponibles sont suffisamment solides pour que la recherche médicale sérieuse s’y intéresse. Suffisamment préliminaires pour qu’on évite les annonces triomphales.
Ce qui est certain : si l’IA médicale doit tenir ses promesses sur le diagnostic précoce, les maladies rares ou la médecine personnalisée, ce ne sera pas en accédant à plus de données centralisées. Ce sera en apprenant à travailler avec celles qui existent déjà, là où elles sont, dans le respect de ceux à qui elles appartiennent.
Sources et références
DKFZ & HPE — Swarm Learning for decentralized AI training, Nature (2021)
OCDE — Global Health Data Access Report (2024)
Nature Digital Medicine — Cross-hospital model generalization failure (2023)
Mayo Clinic — Model performance degradation across populations (2022)
ENISA — Threat Landscape for Healthcare (2025)
Zhu et al. — Deep Leakage from Gradients (2022)
Hitaj et al. — Reconstruction attacks in federated systems (2023)